
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- EKS
- crawling
- module
- ubuntu
- 데이터 분석
- powershell
- sso
- tcp
- 5.0
- Automation
- airflow
- MySQL
- GCP
- ansible
- GIT
- zabbix
- API
- 자동화
- python
- EC2
- 8.0
- DB
- elasticsearch
- ELK
- kibana
- Linux
- AWS
- apt
- 시스템자동화
- Selenium
Archives
- Today
- Total
Oops - IT
Elasticsearch + Kibana - 3 (형태소 분석기 추가) 본문
반응형
저번에 포스팅에서 입력한 Basketball 관련 데이터 입력 시 공백에 따라 데이터가 구분되는 현상을 수정하기 위해
형태 소 분석기 nori를 추가하였고, termvector 데이터 확인 시 최대 3개의 데이터("Golden" + "State" + "Warrios")를 합쳐야 생성가능한 Terms가 있어 max_shingle_size까지 설정해주었습니다.
1. 기존 인덱스 삭제
- 기존 생성되어 있던 인덱스 패턴을 삭제해줍니다.
# curl -X DELETE 'localhost:9200/basketball?pretty'
2. Mapping 파일 수정
- Mapping 파일에 형태소 분석기 내용과 shingle_size 관련 내용을 추가해 줍니다.
- vim basketball_mapping.json
.
.
.
{ "settings": { "analysis": { "analyzer": { "nori_discard": { "tokenizer": "nori_t_discard", "filter": "shingle" } }, "tokenizer": { "nori_t_discard": { "type": "nori_tokenizer", "decompound_mode": "discard" } }, "filter": { "shingle": { "type": "shingle", "token_separator": "", "max_shingle_size": 3 } } } }, "mappings" : { "properties" : { "team" : { "type" : "text", "fields": { "nori_discard": { "type": "text", "analyzer": "nori_discard", "search_analyzer": "standard" } } }, "name" : { "type" : "text", "fields": { "nori_discard": { "type": "text", "analyzer": "nori_discard", "search_analyzer": "standard" } } }, "points" : { "type" : "long" }, "rebounds" : { "type" : "long" }, "assists" : { "type" : "long" }, "blocks" : { "type" : "long" }, "submit_date" : { "type" : "date", "format" : "yyyy-MM-dd" } } } }
.
.
.
: wq
- 위와 같이 형태소 분석기를 추가하고, 기존 team, name Terms에 형태소 분석기를 연결해 주었습니다.

3. 인덱스 및 Mapping 생성
# curl -H 'Content-Type: application/json' -X PUT 'localhost:9200/basketball?pretty' --data-binary @basketball_mapping.json
- 위와 같이 정상적으로 생성되었습니다.

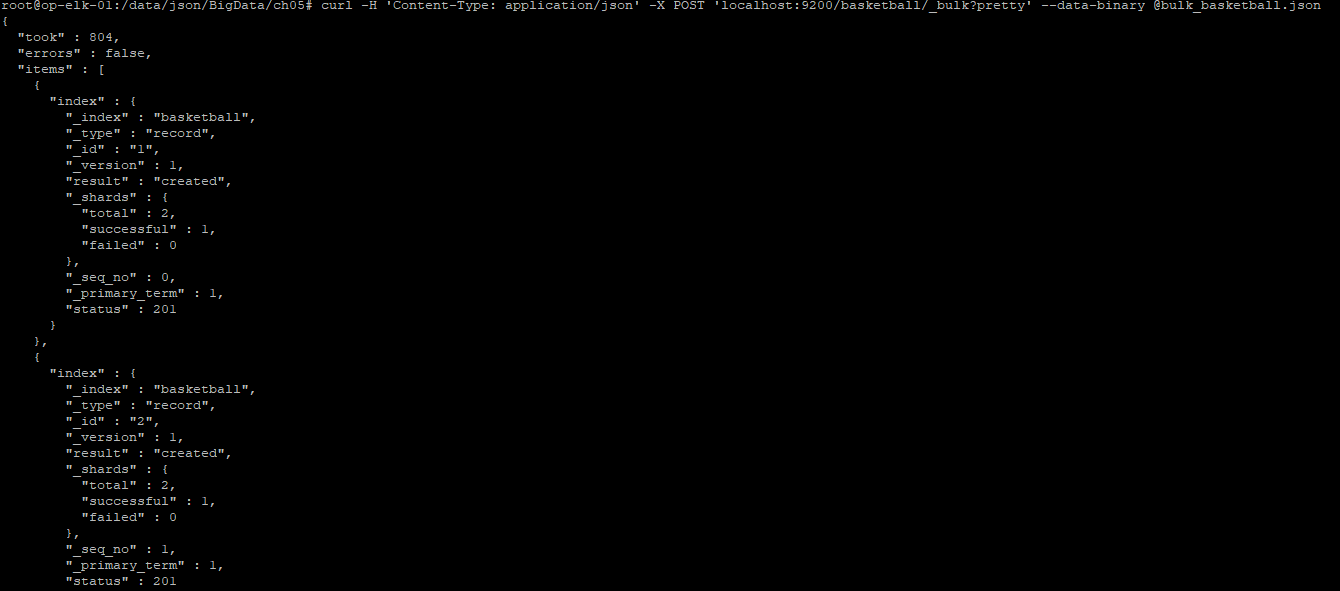
4. 데이터 푸쉬
- 기존 가지고 있는 JSON 데이터를 POST 요청으로 _bulk 쪽으로 보냅니다.
# curl -H 'Content-Type: application/json' -X POST 'localhost:9200/basketball/_bulk?pretty' --data-binary @bulk_basketball.json
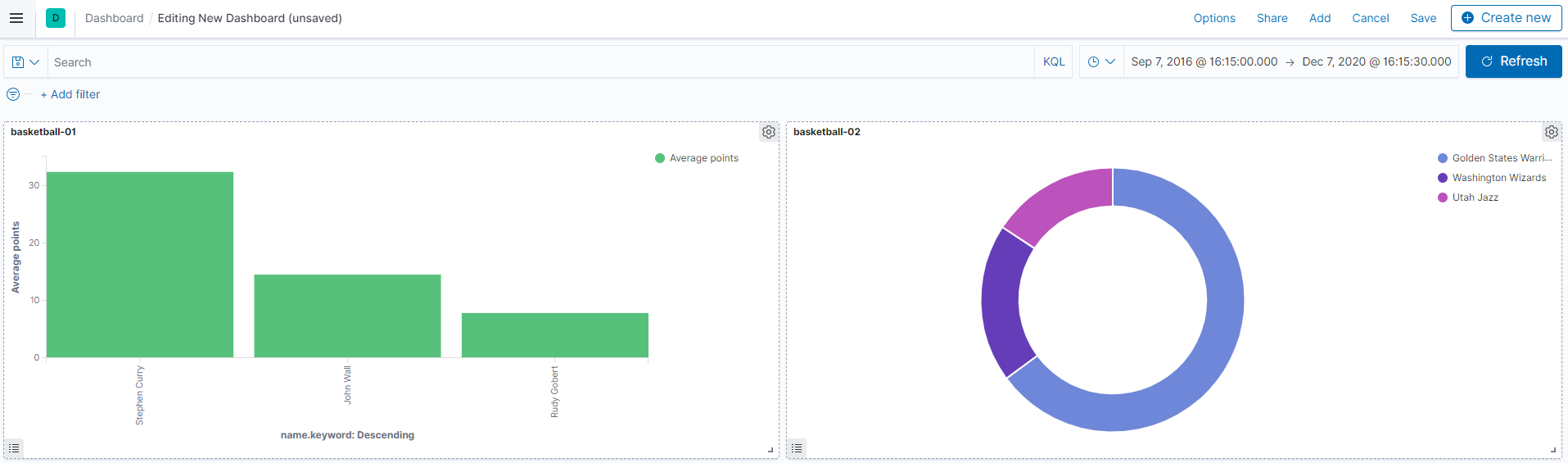
5. 인덱스 패턴 생성 및 데이터 확인
- Kibana 접속 후 기존 인덱스 패턴 삭제 후 재 등록을 해줍니다.
- Visualize 접속 후 데이터 확인 작업을 진행합니다.
- 위와 같이 기존에 공백으로 분리되던 데이터들이 정상 출력되는 모습을 볼 수 있습니다.
반응형
'ELK' 카테고리의 다른 글
| ELK-03 (Filebeat를 연동한 로그 모니터링) (0) | 2020.12.22 |
|---|---|
| ELK - 02 (Zabbix DB 연동 및 데이터 시각화) (0) | 2020.12.11 |
| ELK - 01 (CSV 파일 입력 및 데이터 시각화) (0) | 2020.12.10 |
| Elasticsearch + Kibana - 2 (Elasticsearch 데이터 입력 및 활용) (0) | 2020.12.10 |
| Elasticsearch + Kibana - 1 (Kibana 설치 및 기본 설정) (0) | 2020.12.07 |
'ELK' Related Articles
more



